IQL 介紹
這個文章會簡單介紹 IQL 這篇論文在做什麼。
論文標題: Offline Reinforcement Learning with Implicit Q-Learning
作者: Ilya Kostrikov, Ashvin Nair & Sergey Levine
發表年份: 2021
這篇論文在幹嘛?
這篇是一個 offline 的 reinforcement learning,主要是解決 action out-of-distribution 的問題,簡單來說就是在資料集中沒有出現過的 action 就無法使用,所以在訓練時需要去避免使用它。
為什麼會有「沒出現過的 action」這種問題呢?是因為 offline learning 跟 online learning 的資料來源不同, offline 的資料都是使用由一開始的數據集,online learning 是跟環境做互動後產生的資料,他是邊訓練邊製作資料的。
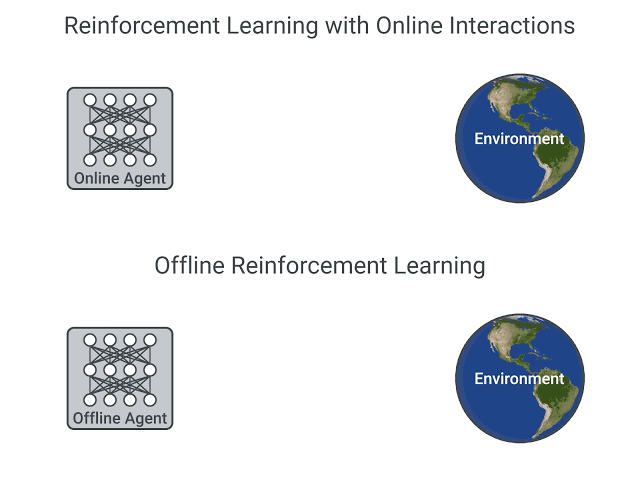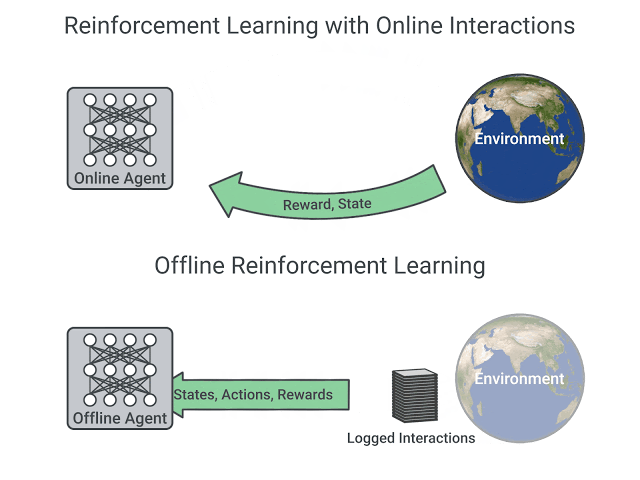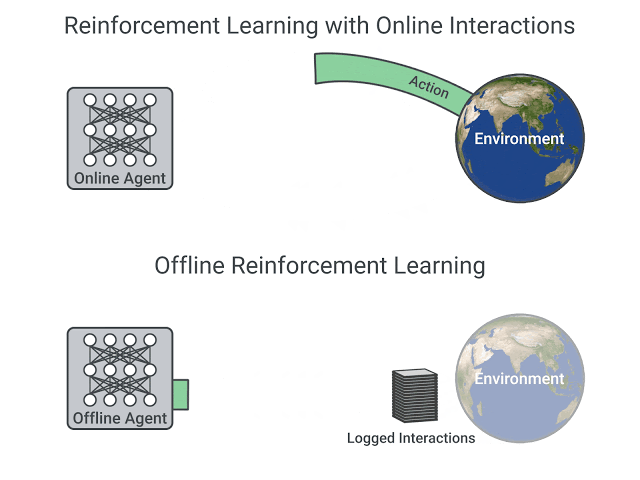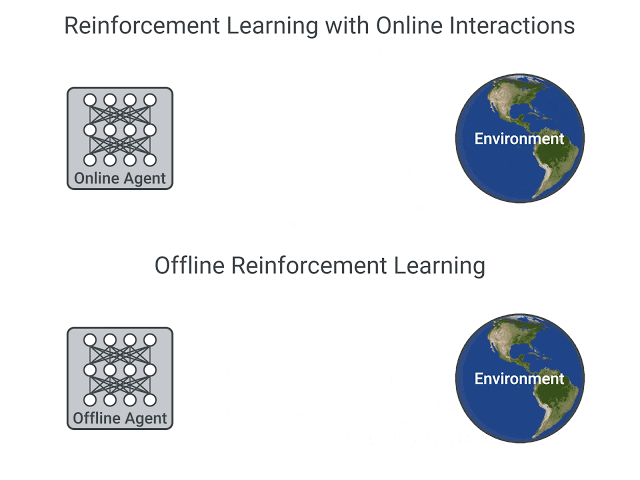
圖片從這個網站抓的
那 offline 這就會出現一個叫 out-of-distribution 的問題,google 中文翻譯叫分佈外,這裡的解釋就是:如果我想知道做一個 action 會產生出的下一個 state 還有 reward ,但剛好資料集沒有這個 action 的資料怎麼辦,那就沒救啦,因為根本沒有資料可以給你參考你要去哪裡找答案。所以下面這個一般常見的 Temporal-Difference (TD) 公式 [1] 就不能用啦。
因為公式的這個部分 會用搜尋在 (也就是下一個 state)的狀態下,有哪一種 action 可以讓 Q 這個 function 最大值,然後再使用 Q function 的數值。那這就不好啦,如果在所有的 action 集合中開始亂找但找到沒出現在資料集裡面的 action 怎麼辦?出事啦阿北。出現 out-of-distribution 了!
那怎麼辦?
所以作者使用了一個特別的方法來避開這個問題。簡單來說他使用了一個像是搜尋讓 Q function 最大值的 action 但又不會找到資料集中沒出現過的 action。這個方法叫做 Expectile Regression!
參考
- Kostrikov, I., Nair, A., & Levine, S. (2021). Offline reinforcement learning with implicit q-learning. arXiv preprint arXiv:2110.06169. ↩
- https://offline-rl.github.io/ ↩